概要
- Chrome が読み上げてくれないページがある
- 読み上げのブラウザ拡張を作ってみようか
- 作り始めたけど課題がいろいろあるな
- なんとかできた
- 実は Edge で便利に読み上げができることがわかったので今後はそっちを使うだろう
背景と始動
前回書いたように、ウェブ記事を Chrome の読み上げ機能でよく聞いている。ただ、ログインが必要なサイトは Chrome は読み上げてくれない。また、一部ログインが不要でもなぜか読み上げてくれないページがある。そして最近 NHK のサイトが大幅に変わって、 Chrome が読み上げてくれなくなった。日々の情報収集において多少の不便となっており、なんとかならんかなと思って解決手段を自作できないかと思案し始めた。Text-to-Speech API エンドポイント叩くだけならそんなに難しくないやろと思って Firefox 用の拡張を自作することにした(10/19 開始)。
最初の構想とプロトタイピング
最初は、Text-to-Speech API とのやり取りを司る公開サーバーを 1 個用意して、ブラウザ拡張から何らかの認証情報とウェブページの内容を表示することでブラウザ上で音声読み上げができるのではないかと考えた。
ブラウザ拡張の作成
ブラウザ拡張をこれまで作ったことなかったので 9 割 vibe coding した。WebExtensions APIs は一切わからなかったし今もわからないけど画面上に表示できたし目的のエンドポイントに POST を投げられるようになった。
バックエンドの作成
遊びで作る小規模なサーバーは最近はすべて Google の edge function 系のサービスを使っている。以前は Cloud Functions というものだったが今は Cloud Run というサービスに吸収された。Cloud Run は Docker image をそのままビルドしてホストする感じなので専用 SDK も不要となりかなり簡単に開発・デプロイできる。そして今回は Cloud Run でホストするエンドポイントを Hono で作ってみた。Hono の感想は後ほど。
実際に試験的に Google の Text-to-Speech API を叩いてみたところ、低スペックの音声モデルでも 8 分ほどの音声の生成に十数秒かかる1ことがわかり、その間にブラウザタブを切り替えたりするとレスポンスが失われることがわかったので別の方法を考える必要が出てきた。
別の方法
音声の生成と取得を非同期で行う方法として思いついたのが下記の 2 通り。
- Web worker か何かを使ってブラウザ拡張のバックグラウンドでレスポンスを待機させてレスポンスが返ってきたらローカルストレージに保存してブラウザ拡張上で音声を再生する
- 非同期で音声を生成するバックエンドをもう一つ用意して、音声データをクラウドストレージに保存して、別途ストレージから音声を返すエンドポイントを作成する
1 つ目は本当に空想で、web worker が何なのかよくわかっていないしブラウザ拡張でそういうことができるのか全くわからなかったので 2 つ目のやり方でやることにした。はじめに想定していたよりもパーツが多くなってしまうが致し方ない。
完成
数週間が過ぎてなんとか出来上がった。下が全体のフローを表した図。

そして再生を行うフロントエンドはこんな感じ。
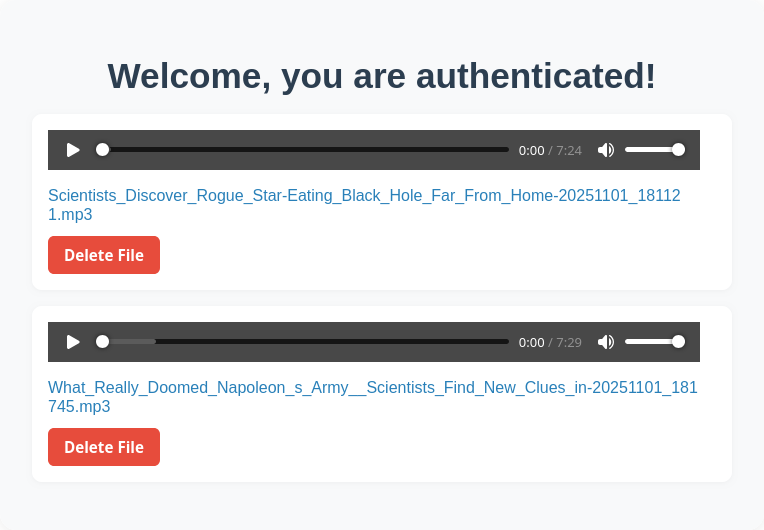
ソースコードを公開することも考えたけど、サーバー間通信で指定するサービスアカウントの情報とかを全部環境変数にいれるのが面倒くさくなって一部ベタ書きになってしまっているので公開はしない。
Edge の読み上げ機能
今日午前中に最終調整が終わって、実際に使ってご満悦だったのだが、もしかして Edge に読み上げ機能あったりしないかなと思いつきで Edge をインストールして使ってみたら見事に存在するし、どんなページも読み上げてくれるし、しかも Chrome よりも人間に近い声で良い感じだったので今後は Edge でウェブページを読み上げてもらうと思う。(終)
全体的な感想
実作業時間は 40 時間くらいだと思う。Gemini と GitHub Copilot と頻繁にやり取りしながら作った。LLM のおかげで明らかに開発スピードが上がっている。正直ブラウザ拡張にあまり興味がないのでそのあたり調べるのも面倒だなと思っていた(思っている)が、そういうのを全部 LLM に書いてもらえるのでかなり開発が楽しい。
Hono の感想
今回は主に下記の機能を触った。
- GET と POST エンドポイントの作成
- React の SSR
- JWT 認証
より大規模な開発ではどんな感じなのかはわからないが、今回使ってみた感じだと非常にわかりやすくて良い開発体験だった。他に TypeScript 系のバックエンドでは NestJS をそれなりに触ったことがあったけど、そっちは裏でいろいろ自動的に処理してしまうので慣れれば便利なのだろうけど、なるべく明示的にデータの流れを追いたい派としては Hono の方が手に馴染む気がした。あと NestJS のデコレータ記法はどうしても好きになれない。
Monorepo で TypeScript の型を共有する
ブラウザ拡張もバックエンドも TypeScript なので monorepo で開発することで型が共有できるじゃん!と開発途中で思って pnpm の workspace とか dto レポジトリを整備したけど、ブラウザ拡張の方の tsconfig が難しすぎてうまく行かず、結局フロントエンドとバックエンドでは別で同じ型を定義することにした。で、今度は Cloud Run にデプロイするとビルドに失敗することがわかり(ディレクトリ単位でデプロイするので当然である)結局 workspace とか dto はすべて消すことになって半日分くらいの作業が吹っ飛んだ。手元でビルドしてからデプロイするフローにすればできるだろうけど、型を共有したいバックエンドが 2 つしかないのでそこまで頑張りたくないと思ってやめた。
IAM と Role と Principal
この辺みんなどうやって管理してるんだろう。途中でこのサービスアカウントは不要なのでは?と思って削除したら動かなくなって、どういう Role を当ててたかが不明でデバッグに沼ったりして大変だった。最終的に動くようにはできたけど、不要な Role を不要なサービスアカウントに与えている気がしている。
著作権メモ
著作権に近いところに所属している以上多少気にしたほうが良いと思ったのでメモとして記録しておく。
今回のケースでは、ウェブ記事という著作物を音声媒体に変換するという翻案を通じて二次著作物を作成し、その二次著作物をウェブサーバーに保存して外部からアクセスできるようにしている。ここで気になったのが下記の 2 点。
- 著作物を私的利用目的で翻案することは問題ないか
- 認証を通じてのみアクセスできるウェブサービス上で音声をホストすることは送信可能化権を侵害しないか
1 点目に関しては、よくわからなかった。私的使用のための複製は原則として著作者の許諾なしで行うことができるが、翻案については具体的な記述がなさそうだった。でも仮に私的使用のための翻案が侵害行為とされるならウェブ記事を音読するのもアウトになるのでおそらく問題ない。
2 点目に関しては、もしアウト判定なら、クラウドに音楽ファイルのバックアップを取る、とかが侵害行為となるのでまあ大丈夫でしょう、というのが直感。
「送信可能化」の定義(第 2 条第 1 項第 9 号の 5)を見ると
次のいずれかに掲げる行為により自動公衆送信し得るようにすることをいう。
とあり、「自動公衆送信」の定義(第 2 条第 1 項第 9 号の 4)を見ると
公衆送信のうち、公衆からの求めに応じ自動的に行うもの(放送又は有線放送に該当するものを除く。)をいう。
とある。読み上げ音声にアクセスするためのページには認証機能を入れているので自動公衆送信に該当しないので問題ないと思われる。
- テキストを分割して並列でリクエストを投げれば時間を短縮できるのではないかと書きながら思った。1 個のリクエストで送信できるコンテンツの制限が 5,000 バイトなので分割は必須だし
Promise.all()使えば簡単に実装できそう。↩